
Preparing for The Chase with AI
If you know me, you probably know I like trivia and pub quizzes. In 2020, this led to me appearing on the Croatian national TV, on the Croatian edition of “The Chase”. Even though I put on a performance to forget by giving five correct answers in the first minute and then getting caught on the chase board, I really liked the atmosphere in the studio and wished to return. Since 2020, I have often thought about applying for my second appearance, and now, in 2025, I have finally done so.
Getting the data
While waiting to be selected for the new season of The Chase, I began thinking about the best method to prepare for the quiz. It didn’t take much browsing to find what appears to be a list of almost 8,000 question-answer pairs that allegedly appeared in the previous seasons of The Chase:
15023.Planetoid Croatia is located in the main planetoid belt so it is located
between which two planets?Mars and Jupiter
17319.Washington monument with 58000 names was erected in memory of victims
of which war?Vietnamese
19274.In which city is Hartsfield-Jackson,the busiest ameriacn
airport by number of passengers?Atlanta
22105.Which teen series have the main characters Brandon,Brenda and Kelly?Beverly
Hills,90210
22392.Who,according to the Gospel of Matthew,spoke the words "Eli!Eli!Lama
Azavtani?!"?Jesus Christ
Note: The dataset is originally in Croatian; English translations in this and following examples are shown for convenience.
As shown, the data set was not properly formatted; it contained ordinal numbers at the start of each question, there were unexpected new lines, no clear boundaries between the question and the answer, etc.
Data Cleaning
RegEx + Search & Replace
After seeing this, I took my favorite tool for textual data cleaning — Regular Expressions and VS Code’s Search & Replace tool.
Expand to see the steps
- Remove the
- Simple Search & Replace, no regex needed
- Check if there are any five digit numbers starting with 1 or 2 followed by a period, that are not the question’s ordinal number
(?<!\n)[1-2][0-9]{4}\.- There are four matches for this regex (the first line of the txt file, and three more lines starting with a space instead of the number), so we fix them manually
- No five-digit numbers that are not the question’s ordinal number
- Remove all new lines that are not followed by the question’s number, replace them with a single space
\n(?![1-2][0-9]{4})- Now all questions and answers are in a single line
- Check if all lines start with question numbers followed by a period
^(?![1-2][0-9]{4}\.)- They don’t, so we need to fix three matches manually
- Remove all question numbers
^[1-2][0-9]{4}\.
- Check if there are any lines with multiple question marks
^(?=(?:.*\?){2,}).*$- There are four matches, so we fix this manually (one contained two question-answer pairs in one line, three contained a quoted question in the text itself)
- After the last question mark of each line, we add a custom separator
<sep>\?(?!.*\?)
- Check if all questions have an answer, i.e., there is some text after the separator
^.*<sep>\s*$- There are two matches, so we’ll add the answers manually
- Remove all white spaces after the separator
(?<=<sep>)\s+
This leaves us with the following list:
Planetoid Croatia is located in the main planetoid belt so it is located between which two planets?<sep>Mars and Jupiter
Washington monument with 58000 names was erected in memory of victims of which war?<sep>Vietnamese
In which city is Hartsfield-Jackson,the busiest ameriacn airport by number of passengers?<sep>Atlanta
Which teen series have the main characters Brandon,Brenda and Kelly?<sep>Beverly Hills,90210
Who,according to the Gospel of Matthew,spoke the words "Eli!Eli!Lama Azavtani?!"?<sep>Jesus Christ
After a RegEx-powered cleaning session, we have a list of questions and answers that we can easily convert to CSV or other nice formats! Running this list through a simple Python script, we get the data in the following format:
question,answer
Planetoid Croatia is located in the main planetoid belt so it is located between which two planets?,Mars and Jupiter
Washington monument with 58000 names was erected in memory of victims of which war?,Vietnamese
"In which city is Hartsfield-Jackson,the busiest ameriacn airport by number of passengers?",Atlanta
"Which teen series have the main characters Brandon,Brenda and Kelly?","Beverly Hills,90210"
"Who,according to the Gospel of Matthew,spoke the words ""Eli!Eli!Lama Azavtani?!""?",Jesus Christ
The only problem is that the questions are full of typos. We’ll try to fix that with an LLM.
GPT-4o Mini + Batch API
No one in their right mind would spend hours fixing typos on almost 8,000 questions and answers, at least not in the LLM era.
I read about OpenAI’s Batch API — a tool that allows you to run thousands of LLM jobs for half their original price. The only caveat is that you don’t get the responses immediately, but you are guaranteed to get them in 24 hours. I made a very simple prompt:
System Prompt:
You are a helpful assistant for Croatian quiz questions.
User Prompt:
Analyze and correct the following Croatian language question and answer.
Question: "{question}"
Answer: "{answer}"
I also instructed it to return the answer in the following format:
class Response:
corrected_question: str
corrected_answer: str
Note: The prompts are originally in Croatian; English translations in this and following examples are shown for convenience.
More info about the Batch API
OpenAI’s Batch API is a great tool for running tasks that don’t require an answer immediately. If you have some coding skills, it’s relatively simple to add thousands of requests to a queue and retrieve the results once they’re done. The great things about the Batch API is that it has much better rate limits, and it’s 50% cheaper compared to the synchronous API!
One thing I noticed when playing with this data is that you can save a lot of time by creating a few smaller batches instead of one large batch. For example, running three batches with about 2,600 questions each took around 25 minutes (you can run them in parallel), while running a single batch with 7,876 questions took more than 3 hours and 30 minutes!
A very simple to follow tutorial can be found here.
Then, I created a list of jobs for the API, uploaded it to the OpenAI Storage, and after waiting a few hours, I got my responses. Running another Python script, I got my answers in a nice format:
corrected_question,corrected_answer
Planetoid Croatia is located in the main asteroid belt. Between which two planets is it located?,Mars and Jupiter
"The Washington Monument with 58,000 names was erected in memory of the victims of which war?",Vietnam War
"In which city is Hartsfield-Jackson, the busiest American airport by number of passengers?",Atlanta
"Which teen series has the main characters Brandon, Brenda, and Kelly?","Beverly Hills, 90210"
"Who, according to the Gospel of Matthew, spoke the words ""Eli! Eli! Lama Azavtani?!""",Jesus Christ
Croatian-specific info about this step
In the LLM typo-fixing step’s structured output, I also had the corrected_answer_nominative property, which allowed me to normalize the answers’ grammatical cases, so it’s easier to compare them and find the answers that occur multiple times. Since English doesn’t have grammatical cases, I felt it was convenient to omit that part.
Data Analysis
Finally, we can start with the fun part. After the previous step, I got quite comfortable with using the Batch API, so I decided to use it to categorize the questions and the answers, and then run an analysis on these categories. I made a few prompts, submitted them to the API, waited a few hours, and now, for each question, I got the following data:
1. Question Category
I used the categories from the official website for applying for The Chase. The topics are as follows:
- Film/TV/media
- Music
- Literature/languages
- Fine art
- History/politics
- Natural and technical sciences
- Religion/mythology
- Sports
- Geography
Each question can have one or multiple categories associated with it.
2. Answer Type
I was not very sure how to approach this, but after some thinking and consulting with ChatGPT, I narrowed it down to the following answer types:
- Person - Names of people, characters, or groups of people (e.g., “Albert Einstein,” “The Beatles”).
- Place - Geographic locations, countries, cities, landmarks (e.g., “Paris,” “Mount Everest”).
- Organization - Companies, institutions, political entities (e.g., “NASA,” “United Nations”).
- Date/Time - Years, dates, or temporal expressions (e.g., “1776,” “Tuesday”).
- Number - Pure numbers not representing dates (e.g., “42,” “3.14”).
- Event - Historical, cultural, or sporting events (e.g., “World War II,” “Olympics 2020”).
- Object/Thing - Tangible or conceptual objects not covered by other categories (e.g., “iPhone,” “Eiffel Tower,” “Quantum Mechanics”).
- Concept/Idea - Abstract ideas, theories, or phenomena (e.g., “Gravity,” “Democracy”).
Each answer can have only one type associated with it.
Category distribution
The first thing I wanted to know was how many questions belong in each category. Since I’m working with multi-label classification, i.e., each question can belong to zero, one, or multiple categories, I needed a good way to visualize this. The best thing I found was an UpSet Plot, which shows both the frequencies of each category and the frequencies of the intersections of different categories.
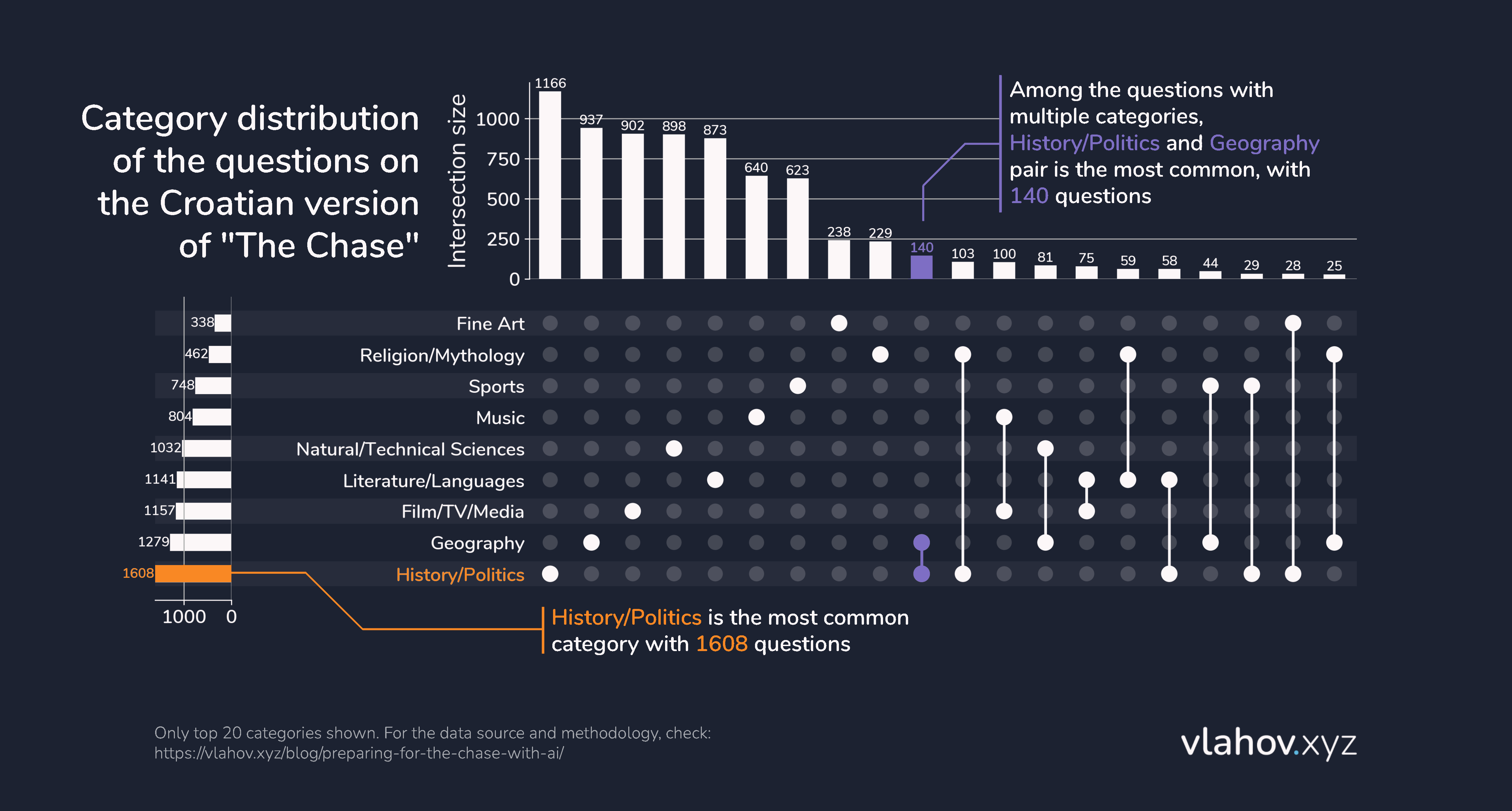
We got some very interesting results — it seems that the History/Politics and Geography categories are the most common, with 1,608 and 1,279 questions, respectively, whereas Religion/Mythology and Fine Art are the least common, with 462 and 338. I was very surprised to see how rare Sports and Music questions are.
As expected, among the questions with multiple categories, the History/Politics and Geography pair is the most common, with 140 questions.
Answer type distribution
The answer type is a much simpler property to visualize since each answer can have only one answer type. We can visualize this with a simple bar chart:
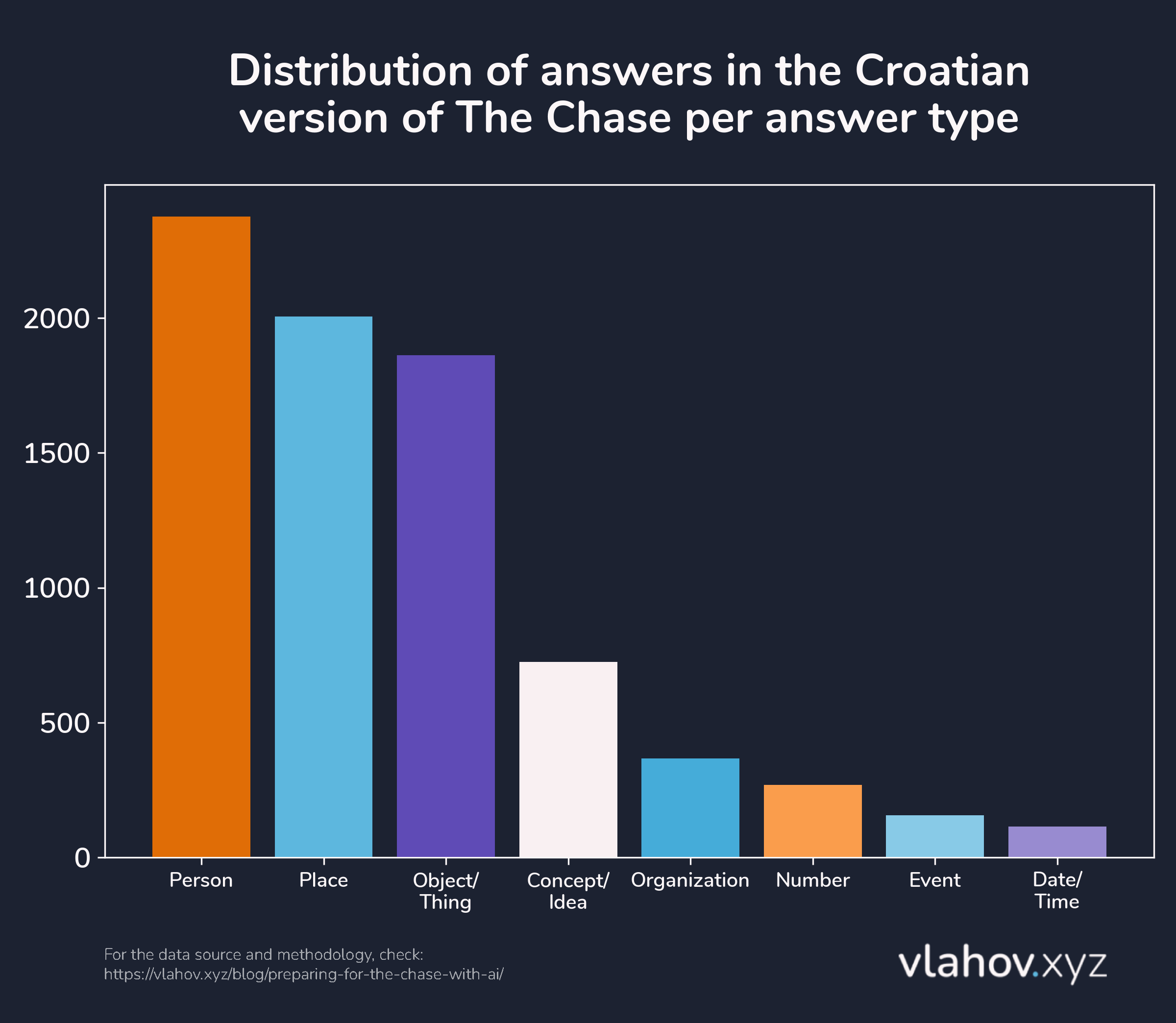
We can see that the most common answer types are Person and Place, with 2,376 and 2,005 answers, respectively, and the least common are Event and Date/Time, with 156 and 115, respectively.
Answer frequencies
Obviously, I also wanted to know which answers appear the most. To visualize this, I chose a word cloud, where each word’s font size is relative to its frequency, and each answer type has its own color.

Note: The answers were translated using Chat GPT.
Very cool. Even though the most common answer type is Person, answers from the Numbers and Places types seem to repeat the most — the answers “3”, “4”, “France”, “2”, and “Italy” are the most frequent answers, occurring 27, 23, 21, 21, and 20 times, respectively.
Named entities breakdown
Answers are interesting, but they don’t tell us all about the overall popularity of certain people, countries, or cities in The Chase. We need to check all mentions of these entities in both the questions and the answers. Once again, we’ll use the Batch API for our task. After the job, for each question-answer pair, we have a list of entities that appear in it.
Question:
Who is the author of the prose work "The Adventures of Arthur Gordon Pym"?
Answer:
Edgar Allan Poe
Entities:
The Adventures of Arthur Gordon Pym, artwork
Edgar Allan Poe, person
Great! We can now compare different entity types, so we’ll start with the most popular people:

I never thought I would see Jesus Christ, Meryl Streep, Dino Dvornik, and Dante Alighieri in the same context… What about sports? What football clubs are mentioned most often?

There’s much more left to explore here, but I think this is a good place to stop. Instead of more analysis, I think I’m off to learn more about History, Politics, and Geography, maybe a few things about Jesus, Napoleon, and Shakespeare, and I’ll surely have to prepare a few fun facts about Hajduk Split and Barcelona… If you enjoyed this analysis and the visualizations, you can follow me on LinkedIn where I share all of my new blog posts.
Notes
There are a few important things to note:
- All of the code, data, and visualizations are available in this repository. There’s also some code, data, and visualizations I did not mention in the post.
- Using the Batch API with GPT-4o Mini is very cheap. This entire analysis $3.83 (3.26€), and that includes multiple test runs that gave bad results.
- I did not take the time to analyze the correctness of the LLM outputs in much detail. This analysis was more of a fun project than something serious. My goal was to try the Batch API, which I found very useful, and to try to apply some of the things I recently learned about data visualization.
- I didn’t measure it, but I felt Named Entity Recognition (NER) outputs made with GPT-4o Mini were not very good. I did not completely trust the outputs, so I analyzed their top 20 results manually in the person and football club categories, and then used these manual analyses to create the graphics.
- I used the following tools for this project:
- RegEx, pandas, ChatGPT and OpenAI Batch API for data cleaning
- matplotlib, upsetplot, wordcloud for chart creation
- vlahov.xyz brand colors and Photopea for creating custom visuals
- I found the original data set in the Anansi project
- All images used in the graphics were taken from Wikipedia